Task: to present near real-time (or batch) enterprise search platform built on the Apache Lucene project
Cloudera Search offers the following methods for indexing data at scale:
- NRT indexing (Lily HBase NRT indexing or Flume NRT indexing)
- batch indexing (Spark or MapReduce indexing: MapReduceIndexerTool or Lily HBase batch indexing)

Architecture: NRT Cloudera Search
Environment:
- Hadoop (big data) cluster: Cloudera (either an existing Cloudera infrastructure or Cloudera Quickstart VM)
- Cloudera Search services: HBase with ZooKeeper, Key-Value Store Indexer (Lily NRT HBase indexer) and Solr; supporting services: Cloudera Manager, Hue, HDFS and YARN (with MapReduce included)
- data ingestion: e.g. Talend Open Studio / Solr UI update (optional)
- testing: Solr UI select / SOAP UI (optional)
Setup:
a) creating/enabling HBase table ‘Solr_Test’ with column family ‘cities1000’ and enabling replication for Lily HBase NRT indexing
hbase shell
create 'Solr_Test', 'cities1000'
alter 'Solr_Test', {NAME => 'cities1000', REPLICATION_SCOPE => 1}
enable 'Solr_Test'

Listing: HBase shell
b) creating Solr collection ‘solr_test-collection’ and schema ‘schema.xml’
solrctl instancedir --generate $HOME/solr_test-collection
download: schema.xml
solrctl instancedir --create solr_test-collection $HOME/solr_test-collection solrctl collection --create solr_test-collection

Listing: Solr shell
c) creating Lily HBase configuration files: ‘morphlines.conf’ and ‘morphline-hbase-mapper.xml’ and adding indexer
download: morphlines.conf
download: morphline-hbase-mapper.xml
hbase-indexer add-indexer \ --name SolrTestIndexer \ --indexer-conf $HOME/solr_test-collection/conf/morphline-hbase-mapper.xml \ --connection-param solr.collection=solr_test-collection \ --zookeeper quickstart.cloudera:2181

Listing: HBase indexer
hbase-indexer list-indexers

Listing: HBase indexers
d) additional settings
URL: http://quickstart.cloudera:7180
Key-Value Store Indexer -> “logging”
log4j.logger.org.kitesdk.morphline=TRACE
log4j.logger.com.ngdata=TRACE

Lily: logging setting
Cloudera Manager -> Clusters -> Key-Value Store Indexer -> Configuration
Java Heap Size of Lily HBase Indexer in Bytes -> 50 MB -> e.g. 1 GB (based on the input)

Lily: heap size setting
Cloudera Manager -> Clusters -> HBase -> Configuration
Java Heap Size of HBase Master in Bytes -> 50 MB -> e.g. 1 GB (based on the input)

HBase: heap size master setting
Java Heap Size of HBase RegionServer in Bytes -> 50 MB -> e.g. 1 GB (based on the input)
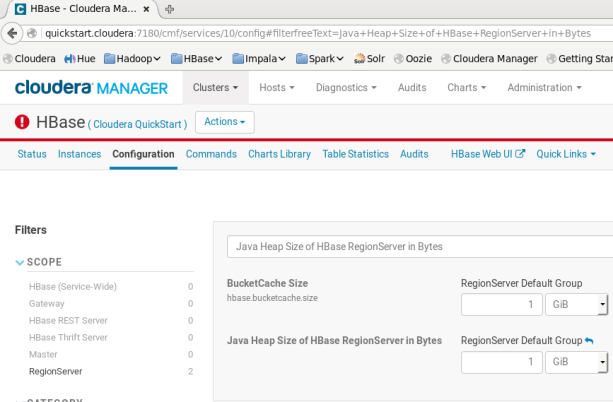
HBase: heap size region setting
e) verifying that the indexer works
URL: http://quickstart.cloudera:8983

Solr: indexer (empty)
Note: HBase indexer log file: /var/log/hbase-solr/ lily-hbase-indexer*.log.out
f) data ingest

Talend: data ingestion

Hue -> HBase: ingested data
Optional Solr data ingest in form (note: not related to HBase part!):
http://quickstart.cloudera:8983/solr/solr_test-collection_shard1_replica1/update/csv?commit=true&separator=%09&fieldnames=id,name
,,alternative_names,latitude,longitude,,,countrycode,,,,,,population,elevation,,timezone,lastupdate&stream.file
=/home/cloudera/solr_test-collection/cities1000.txt&overwrite=true&stream.contentType=text/plain;charset=utf-8
g) testing
URL: http://quickstart.cloudera:8983
At this point, if you run data ingestion (e.g. via job in Talend), in a matter of few seconds (i.e. near real-time), you will receive new data as result to query in Solr.

Solr: indexed data (documents)

Solr: query result
Field q (in query) accepts format field:value and accepts wildcard symbols.
{
"responseHeader": {
"status": 0,
"QTime": 1,
"params": {
"indent": "true",
"q": "name:Botta*",
"_": "1544275090709",
"wt": "json"
}
},
"response": {
"numFound": 2,
"start": 0,
"docs": [
{
"countrycode": "IT",
"alternative_names": "Bottanuco",
"elevation": "222",
"id": "3181668",
"lastupdate": "2014-04-13",
"timezone": "Europe/Rome",
"name": "Bottanuco",
"longitude": "9.50903",
"latitude": "45.63931",
"population": "5121",
"_version_": 1619289130669179000
},
{
"countrycode": "IT",
"alternative_names": "Botta",
"elevation": "",
"id": "9036161",
"lastupdate": "2014-05-20",
"timezone": "Europe/Rome",
"name": "Botta",
"longitude": "9.53257",
"latitude": "45.83222",
"population": "751",
"_version_": 1619289135325905000
}
]
}
}
Optional SOAP UI REST: http://quickstart.cloudera:8983/solr/solr_test-collection_shard1_replica1/select?q=name%3ABotta~&sort=score+desc%2C+name+asc&rows=6&fl=name%2C+score&wt=xml&indent=true

SOAP UI: REST query result
Abbreviations
- EDH: enterprise data hub
- DL: data lake
- NRT: near real-time
Sources
References
